This blog post is part two of a two-part series. (Find part one here.)
Hello there! Welcome to the second part of this article in which we'll discuss a bit about directors and how to use them as well as an introduction to load balancing. The first part was about backends and probes, so if you don't know about them already, it's probably a good start to read it first. Go ahead, I'll wait.
Ready? Good!
Let's look back at our VCL from the previous post:
backend alpha { .host = "192.168.0.101"; }
backend bravo { .host = "192.168.0.102"; }
sub vcl_recv {
if (req.http.host == "alpha.example.com") {
set req.backend_hint = alpha;
} else if (req.http.host == "bravo.example.com") {
set req.backend_hint = bravo;
} else {
return (synth(404, "Host not found"));
}
}
This allows us to route requests to the correct server, but I'm pretty sure none of you, smart cookies that you are, would be content with just one backend per domain. So much can go wrong, from floods to aliens to the intern unplugging the server to recharge his phone (Pokémon GO is such a battery hog!). Hence you will want to add some redundancy to the mix, so add two servers:
backend alpha2 { .host = "192.168.0.201"; }
backend bravo2 { .host = "192.168.0.202"; }And you'll plan on doing some round-robin with each pair (alpha/alpha2 and bravo/bravo2). But how can we do that?
Just for the sake of it, let's have a look at one possible VCL implementation (using vmod-var). It's probably not the best one, and it's also not a true round-robin because of concurrency issues, but close enough:
import var;
backend alpha1 { .host = "192.168.0.101"; }
backend alpha2 { .host = "192.168.0.201"; }
backend bravo1 { .host = "192.168.0.102"; }
backend bravo2;{ .host = "192.168.0.202"; }
sub vcl_init {
var.global_set("alpha_rr", "1");
var.global_set("bravo_rr", "1");
}
sub vcl_recv {
if (req.http.host == "alpha.example.com") {
if (var.global_get("alpha_rr") == "1") {
set req.backend_hint = alpha1;
var.global_set("alpha_rr", "2");
} else {
set req.backend_hint = alpha2;
var.global_set("alpha_rr", "1");
}
} else if (req.http.host == "bravo.example.com") {
if (var.global_get("bravo_rr") == "1") {
set req.backend_hint = bravo;
var.global_set("bravo_rr", "2");
} else {
set req.backend_hint = bravo2;
var.global_set("bravo_rr", "1");
}
} else {
return (synth(404, "Host not found"));
}
if (!std.healthy(req.backend_hint)) {
return (synth(503, "No healthy backend"));
}
}
So, yeah, that works, but is it really satisfying? I mean, we are talking about a simple round-robin with two servers here, and the code is already becoming unwieldy, plus, think about adding a third or fourth server to the clusters. That code will soon become unmaintainable. Fortunately, we have a better way: directors! And the first one you will see is the round-robin director.
A director is an object, provided by a VMOD, describing a set of backends combined with a selection policy. In the round-robin case, the policy is... well... round-robin. That was kind obvious.
With it, our example becomes:
import directors;
backend alpha1 { .host = "192.168.0.101"; }
backend alpha2 { .host = "192.168.0.201"; }
backend bravo1 { .host = "192.168.0.102"; }
backend bravo2;{ .host = "192.168.0.202"; }
sub vcl_init {
# first we must create the director
new alpha_rr = directors.round_robin();
#then add the backends to it
alpha_rr.add_backend(alpha1);
alpha_rr.add_backend(alpha2);
# do the same thing for bravo
new bravo_rr = directors.round_robin();
bravo_rr.add_backend(bravo1);
bravo_rr.add_backend(bravo2);
}
sub vcl_recv {
# pick a backend
if (req.http.host == "alpha.example.com") {
set req.backend_hint = alpha_rr.backend();
} else if (req.http.host == "bravo.example.com") {
set req.backend_hint = bravo_rr.backend();
} else {
return (synth(404, "Host not found"));
}
if (!std.healthy(req.backend_hint)) {
return (synth(503, "No healthy backend"));
}
}
Much better! Now, adding a server to a cluster is only a matter of adding a new line with ".add_backend()" in vcl_init, one point for maintainability.
We also reap one extra benefit from using the round-robin director: it will filter out all the unhealthy backends in its pool before selecting one, meaning it won't return a sick backend and that's something that wasn't done in your VCL implementation. If all its backends are sick, it will return a big nothing ("NULL", actually), and in this case, in our code, std.healthy() will return false, correctly triggering the error. And all of it is done automatically because we have configured our probes correctly in our previous article.
Let me weigh in on something
Acute readers will have noticed that I wrote about simple round-robin, eluding the "weighted" variant, and the reason for this is simple: Varnish doesn't have one!
My take on this is that we don't really need it because we have the random director in vmod-directors. It allows you to add backends to it, exactly as before, but with one extra parameter: the weight:
import directors;
backend server1 { .host = "127.0.0.1"; }
backend server2 { .host = "127.0.0.2"; }
backend server3 { .host = "127.0.0.3"; }
sub vcl_init {
new rand = directors.random();
rand.add_backend(server1, 4);
rand.add_backend(server2, 3);
rand.add_backend(server3, 3);
}
Then, when h.backend() ran, it will roll a 10-sided dice. Check out the result:
- 1-4: return server1.
- 5-7: return server2.
- 8-10: return server3.
So, on average, server1 gets 40% of the request, and server2 and server3 30% each. The difference with a weighted round-robin (wrr) policy is that there's no global context, so it's cleaner and easier to code, removing concurrency issues while maintaining the average spread across servers.
The negative point is that often, people fear that the PRNG (aka the dice-roller) will go all Debian on them and, in a streak of stubbornness, will send 1000 consecutive requests to the same server, killing it with extreme prejudice.
To be fair, that's a mathematical possiblity; however, in the few years I've been working with Varnish, it has never been an issue. I know we live in a cloudy age where you can spawn thousands of identical server with just one command, but if you ever need a weighted content spread, please give this little guy a try, you won't regret it.
Failure is not an option, but it's good to have a backup plan anyway
Round-robin and random directors are fine for active-active setup, but what if you need an active-passive one? You could have an "error backend" used to deliver pretty error pages, instead of a synthetic page as we are currently doing in our VCL. And when I say "pretty", you can assume "large", so that's not something you want hardcoded in your VCL, plus, it's easier to just let the web designers have their own backend and just point Varnish to it.
Turns out the vmod-directors also has the answer to this (in case you doubted it, everything is staged here) with the fallback director: this one will keep the backends in a list and simply offer the first healthy one, so if the first one is always healthy, it always gets picked.
At this point, I'm sure you can figure out how to use it, so let's mix things up and learn something new with this example:
import directors;
backend alpha1 { .host = "192.168.0.101"; }
backend alpha2 { .host = "192.168.0.201"; }
backend bravo1 { .host = "192.168.0.102"; }
backend bravo2 { .host = "192.168.0.202"; }
backend err { .host = "192.168.0.150"; }
sub vcl_int {
new alpha_rr = directors.round_robin();
alpha_rr.add_backend(alpha1);
alpha_rr.add_backend(alpha2);
new bravo_rr = directors.round_robin();
bravo_rr.add_backend(bravo1);
bravo_rr.add_backend(bravo2);
new alpha_fb = directors.fallback();
alpha_fb.add_backend(alpha_rr.backend());
alpha_fb.add_backend(err);
new bravo_fb = directors.fallback();
bravo_fb.add_backend(bravo_rr.backend());
bravo_fb.add_backend(err);
}
sub vcl_recv {
if (req.http.host == "alpha.example.com") {
set req.backend_hint = alpha_fb.backend();
} else if (req.http.host == "bravo.example.com") {
set req.backend_hint = bravo_fb.backend();
} else {
return (synth(404, "Host not found"));
}
}
THE CROWD GOES WILD! We are adding a director to a director! And the thing is, it works exactly as you think it would:
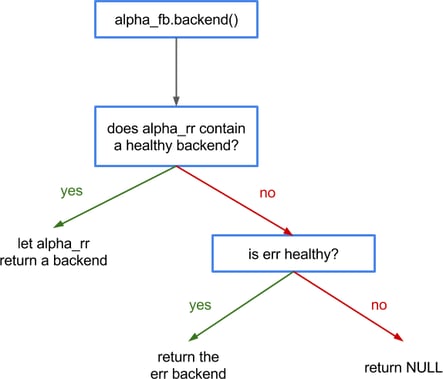
To explain how it works, I have to let you in on a little secret: internally, backends and directors are the same object, the difference being in a few methods implemented by one but not the other and vice-versa. So, we can easily define the health of a director recursively: if any of its sub-directors or backends is healthy, then the director is healthy.
And as said earlier, directors will filter out sick backends, and so sub-directors before a selection, hence the flowchart describes exactly what our intuition predicted.
Also, note that the err backend is defined once, but added to two directors, enabling some pretty crazy setups. Of course, the probe belongs to the backend, so a backend won't get probed twice as much because it's in two directors. That may seem an unnecessary precision, but I've been asked about it, and I'm sure that can benefit others, so, here you go.
Advanced load-balancing: more loaded, more balanced
Up until now, we only dealt with backends with fixed content: alphaX and bravoX contained respectively the alpha.example.com and bravo.example.com domains and err contained the error pages.
But in what we'll see next, we'll let the director decide what backend to use, based on the request, so that we can consistently go fetch the same content on the same machine. Unsurprisingly, the methods will look like:
new hash = directors.hash();
hash.add_backend(alpha1, 3);
hash.add_backend(alpha2, 4);
set req.backend_hint = hash.backend(req.url);
Two points worth noting here:
- this director is also weighted, pushing more requests to the heavier backends.
- the .backend() method takes a string as input (here I gave the request's URL, but it can be any string), and given the same set of healthy backends, with the same weights, the same string input will return the same backend.
You're probably thinking "Ok, but for a given string, how do I know what backend will be returned?", and while it's a very valid question, I only have a disappointing answer for you: you don't, and you don't need to. It's the same concept as for databases: you don't need to know the address where the information is stored, you just need to know that you can access it again by using the same key.
Sadly, we can't use this to split our traffic between alpha and bravo machines, but we can still do something pretty sexy. Let's look at a simplified setup:
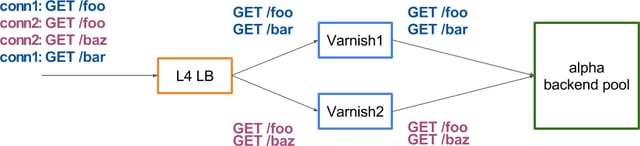
A layer-4 (TCP level) load balancer is often used because they are fast, simple to put in place and you get Direct Server Return, which is neat when you need to deliver high volumes. However, they work at the connection level, so, as is the case here, you can end up requesting content that is already cached, just not on the selected server just because the load balancer is oblivious to the HTTP layer. It's probably not too bad from Varnish1 and Varnish2, but it means we hit the backend more than we "should".
The solution is to replace the L4 balancer with Varnish and to use the hash director (nb: there's no point in using the round-robin director because, again, the two /foo requests would end up on two different Varnish servers). That Varnish server has no ambition to cache any content, and will just pass requests (meaning: no need for a lot of RAM or disk, just some good NICs), leaving the caching to Varnish1 and Varnish2.
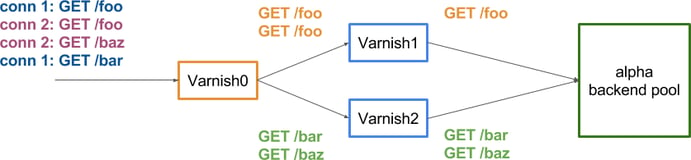
That's more like it! The connection grouping of requests is not an issue any more as only the url is important, and as planned, the two /foo requests go to the same server. Please note that almost all distributions are possible, I only put /bar and /baz together for symmetry. For example, all requests could have been hashed to the same server, the only constant being that the two /foo requests have the same hash and so go to the same caching server.
note: And there's a funny parallel/contradiction to show here with the random director: mathematically, there's a chance that you receive a thousand requests that all get hashed to the same server, but somehow, that doesn't prevent people from using it.
Diminishing backend pressure is only one of the advantages of using Varnish in front of the caching layer. As we removed duplication of content, we effectively doubled our cache capacity! And every new server added will give us more capacity in addition to more bandwidth, whereas in a round-robin setup we'd only gain bandwidth (instead of adding servers to expand storage, you can also look at the Massive Storage Engine, just sayin').
But (there's always a "but"), we lost something along the way, and I'm not talking about freckles or sense of wonder. No, I mean redundancy. If either Varnish1 or Varnish2 falls, the cached objects in them are gone, because as we wanted, there's no content replication any more (which was the whole point of the setup, so we can't really complain).
Looks like you can't have your cake and eat it
Or can you? Remember that you can stack directors? Let's do just that :
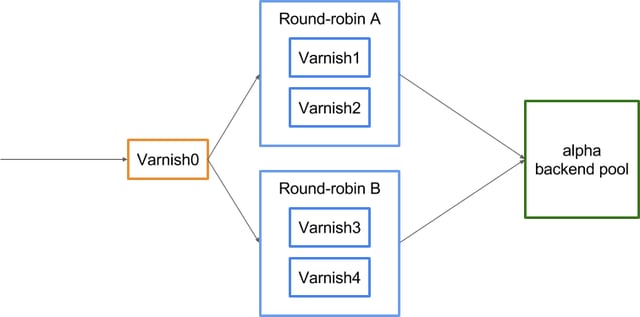
By hashing toward a round-robin pool, we get to have increased caching storage, AND keep the redundancy. By adding more round-robin pools we gain cache capacity, and by adding servers in them, we increase redundancy.
Buuuuuuuuuuuut (see? I told you), we are back to the initial backend pressure, since we'll cache the same content on both Varnish servers inside a pool. That can be an issue, indeed, but fortunately, we have a tool for this: Varnish High Availability can replicate content smartly without bothering the backends, allowing for retention of the cache capacity and redundancy without straining the backends. So you CAN have your cake, eat it, and not even gain weight!
note: the number of Varnish servers inside the round-robins is the only factor in computing the backend strain, adding more pools won't help, or worsen (but they'll expand your storage capacity).
What lies beyond
Time to wrap up! We are done with our introduction to directors and load balancing in Varnish, and I hope this article gave you a few ideas on how you can leverage all this in your particular setup. If you have questions on remarks about how to better use directors, please reach out to me on IRC or twitter and share your experience!
Also, consider that we only looked at a very small part of the landscape, i.e., the directors that are readily available with Varnish, but since directors are VMODs (since 4.0), they are easy to create and use, so if your own need isn't fullfilled, have a look around Github for example, the VMOD you want may already exist.

Photo (c) 2007 Adrian Clark used under Creative Commons license.


