
Lately the content delivery industry looks more like a meteorological website for alpinists than anything else.
I’m sure you have heard on more than one occasion words, such as “cloud”, “fog” and “edge” in conjunction with words like “computing” or “logic”. At this point, unless you read articles about these topics every day (that’s part of what I do for a living), I’m quite sure you are confused about what each of them really means in the context of content delivery.
Let’s keep the mountain analogy: after a morning hike, you have reached the edge of the mountain and a thin layer of fog surrounds you, and it sits between you (on the edge) and the cloud(s).
The exact same logic can be applied to any content delivery network where the cloud layer usually sits quite far away from end-users, while the edge is extremely close to the end-user.
The fog is not always present, but it can be implemented as extra layer in between the cloud and the edge to further optimize the whole architecture.
Up in the clouds
Sooo...what is the cloud, and most importantly why the heck is it called “cloud”?
We have to go back to the early days of networking design where the cloud icon was used by network engineers to represent anything standing between two or more different networks. Basically the cloud was used to indicate “the internet” in toto.
In the years since its introduction, the cloud has assumed a slightly different meaning and today is by default associated with a server, living most likely in an unknown location, which is used to store, process and collect content. Yes, I know you are thinking about the Apple cloud and that’s exactly what the cloud is all about: the end-user only cares about uploading pictures, songs, contacts and content and rely completely on someone else to provide the storage and its maintenance.
Obviously the idea of only managing content and not taking care of the networking and hardware part of things has proved to be appealing not only for the single end-user, but also for bigger companies, which in the last 10 years or so have started a mass migration from bare metal to cloud solutions. This means that many companies don’t own the infrastructure any more, but rent it from a third party that takes care of its complete maintenance, which is also known as IaaS (infrastructure as a service) or, in more advanced scenarios where both infrastructure and software solutions are provided, SaaS (software as a service).
While cloud computing was merging and expanding throughout all the kind of businesses, more data and content was constantly being produced. We reached a point where the real problem was no longer related to the way the content was produced or stored; instead, the main bottleneck was the network, which has proved to have severe limitations… hence, the fog.
Edging our way through the fog
Fog computing is a term Cisco developed for extended cloud computing. It was born in the attempt to run some logic either on the network itself or on a hardware layer closer to the end-user and edge devices.
The idea is to bring some logic closer to the edge (hence 'edge logic') because there is no real need to send all traffic generated at the edge of the architecture back to the cloud.
The fog was born for mainly three reasons:
- To reduce the amount of data shuffled back and forth from the cloud
- To decrease network latency and bandwidth usage
- To improve system response time in remote applications
Until a couple of years ago it was all about cloud and fog computing, but then, with the arrival of IoT (internet of things), IoE (internet of everything) and big data, the need to process the traffic even closer to the end-user arose. And edge computing arrived.
Edge computing moved logic processing even closer to end-users, and most of the data collection and filtering happens within the devices themselves. Data is first refined and then eventually sent either to the fog or cloud layers. The aim of edge computing then, in the content delivery context, is to reduce the bandwidth used, as again bandwidth is still an expensive and limited resource, and improve response times, which will lead to more happy consumers.
Wrapping up
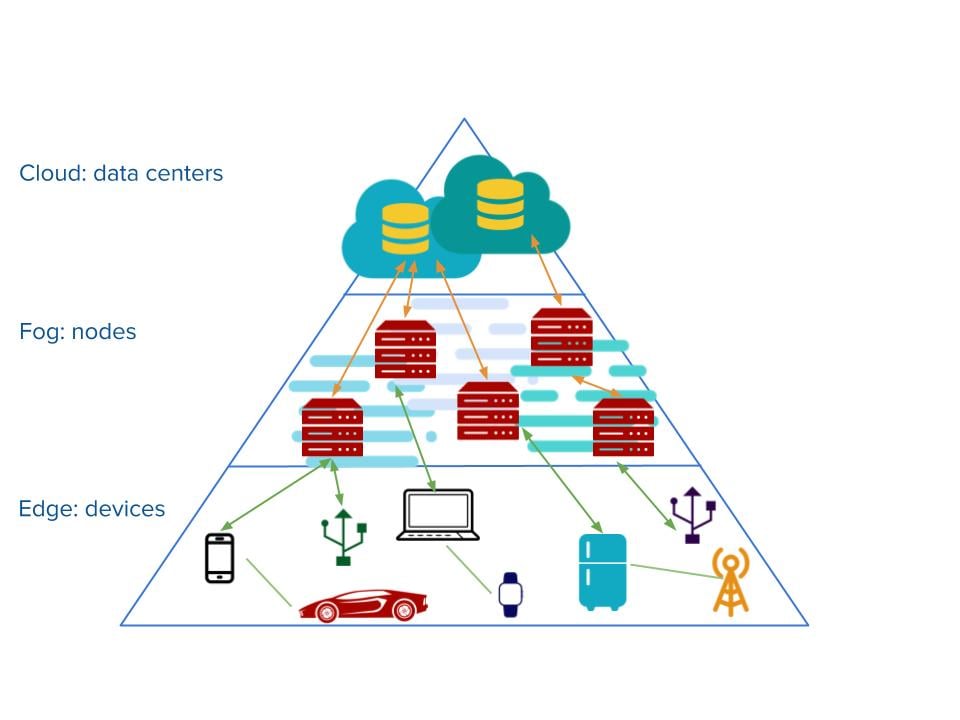
Fog and edge computing are the natural evolution of the cloud, as each of the three layers aims to improve performance and have highly configurable nodes within the same architecture.
Hopefully this blog post makes it easier to understand the main differences between clouds, fog and edge computing as they are here to stay in the years to come - and more and more, if not most, companies will adopt at least one of the three to strengthen and customize their content delivery strategies.
There's still time to sign up for our 15 May live edge webinar, co-hosted by analyst firm RedMonk. Join us to learn what edge computing is and when and why to use it.



