
Varnish High Availability (VHA) is a high-performance content replicator for Varnish Plus. Using VHA with a group of Varnish Plus servers ensures that the cached objects will be efficiently replicated between caches when first fetched from the backend. This both provides higher performance to the client, and minimizes backend traffic.
Benchmark setup
To illustrate the performance benefits of using Varnish High Availability, a cluster of 6 Amazon EC2 nodes was configured in a setup as illustrated in Figure 1 and detailed in Table 1.
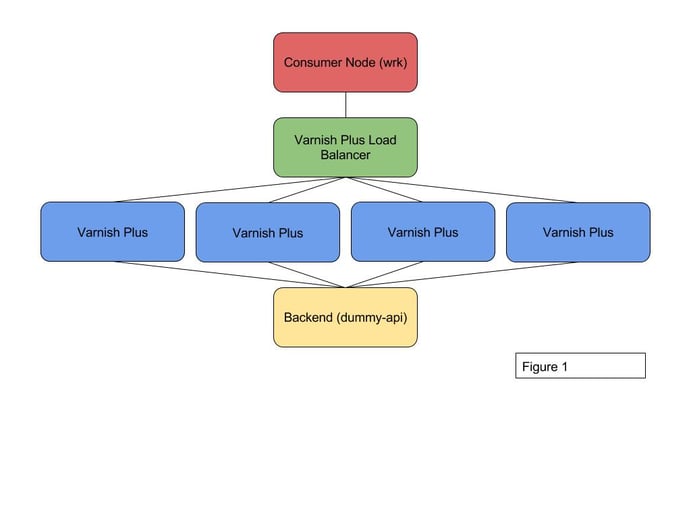
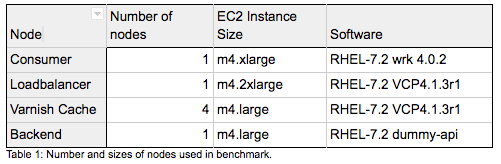
The consumer node is set up with the “wrk” tool, a high-performance benchmark client that is able to generate significant load on relatively low-powered nodes. The backend used is a synthetic golang-based backend that, based on the request URL, will generate custom responses that are useful in a benchmarking context.
For this benchmark, a URL set was generated with 50,000 unique URLs. The backend requests generated by the URLs instruct the backend to start serving data after a 200ms pause. This is done to simulate a real-life backend, which performs logic on each request. Size distribution was set to between 10,000 and 50,000 bytes.
At the start of the benchmark run, the cache is cleared on all Varnish Plus nodes. The url-list is used to generate load for 90 seconds, then the list is processed from the top again for a total of three passes. This illustrates a scenario where the cache is emptied, due to a site-wide content update or other similar events, and users accessing the various content over time, with hit rates increasing as more content is inserted into the cache.
At the end of the benchmark run, the number of backend requests is tallied along with the performance counters from the wrk tool.
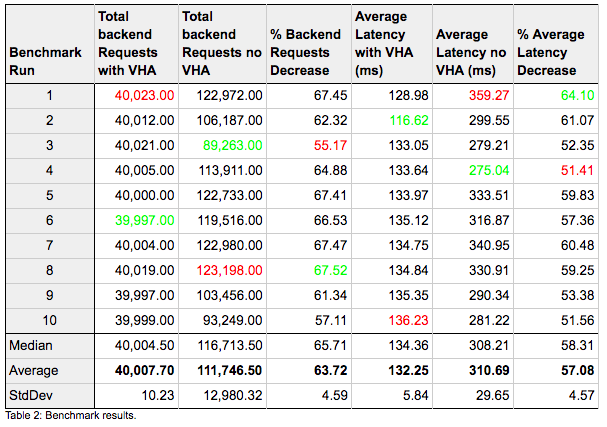
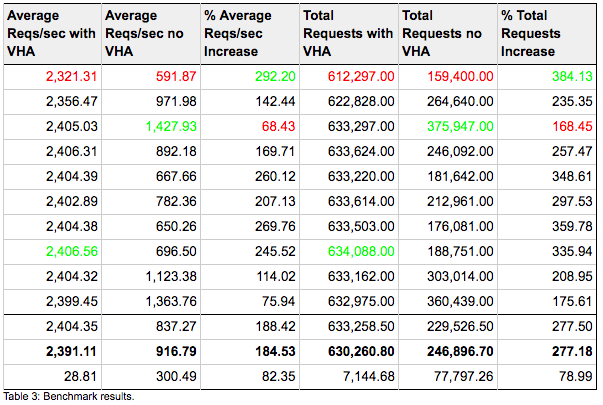
The benchmark set was repeated 10 times, results are shown in Tables 2 and 3 below.
Comparing results
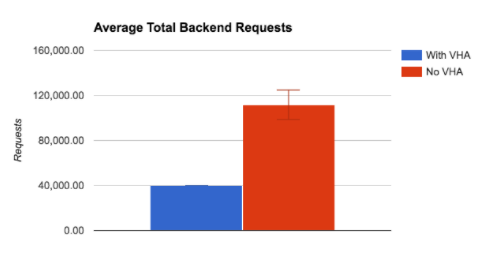
Comparing the results from the benchmark runs with Varnish High Availability enabled versus the disabled runs, the backend offloading is immediately apparent. With VHA enabled, the backend requests were decreased by between 55% to 67% (an average of 63% decrease across all ten benchmark runs).
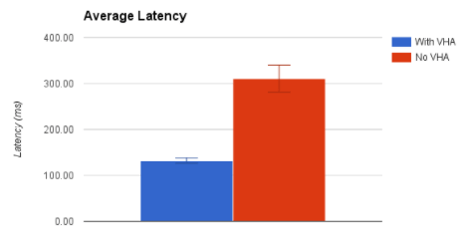
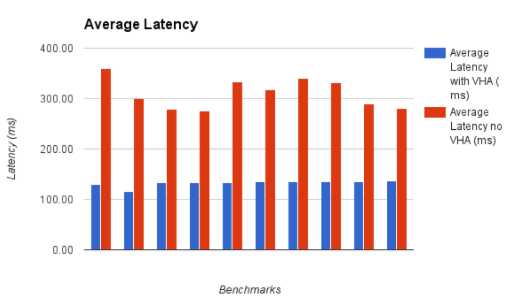
The request latency decreased by between 51% to 64% (with an average of 57% decrease across all runs) as fewer requests required additional round trips to the backend. With VHA the latency is also kept a lot more consistent, with lower standard deviation in the measurements.
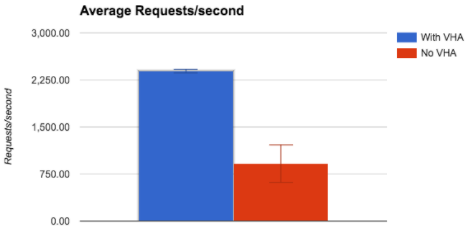
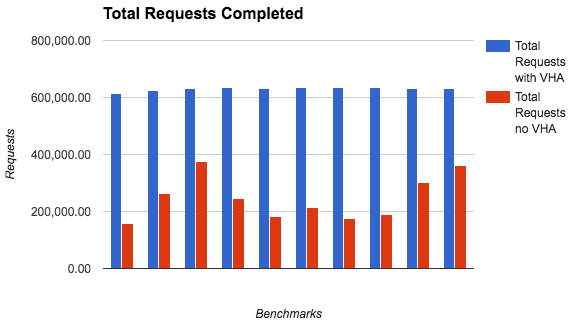
The transactional capacity measured in requests/second is also greatly improved when Varnish can deliver directly to the client. The average increase is between 68% and 292% (with an average increase across all runs of 184%). Looking at the amount of completed requests, using VHA we get a consistent performance of over 600k requests completed per benchmark run. Without content replication the average result is 246k requests, with a wide spread between 159-376k requests completed.
Real-life impact of using VHA
Any synthetic benchmark result will always be difficult to extrapolate directly over to real-life results. However, the performance characteristics shown in these benchmarks illustrate in which ways content replication with VHA improves performance in a cache cluster.
The usage patterns of high-volume websites tend to benefit from cache replication. The hot-set of objects, be it front pages, top news stories or hot e-commerce products, is important to keep in cache, and in a multi-cache cluster, replication ensures that updates to these objects are quickly inserted into all caches, keeping hit rates across the cluster high.
This means that when using Varnish High Availability, adding more cache servers translates directly into better performance of the environment. Without content replication, adding more caches will often just move the bottleneck to the backend, as cache hit rate per server decreases, and more backend requests are performed as a result. With VHA, backend overloading is avoided. Client delivery is also improved, as higher hit rates translate into improved transactional capacity and lower request latency.
Give Varnish Plus a spin to experience the performance effect of Varnish High Availability.

Photo (c) 2016 European Southern Observatory used under Creative Commons license.