
There's a recurring discussion I get myself into, and it goes roughly like this:
- I want to stream live video, what kind of machine, and how many of them do I need?
- It depends.
- Depends on what?
- Math! Also, numbers!
- ...
- Joking, can you tell me <list of characteristics>
- <provides value>
- <performs black magic>. The answer to your question is <scarily accurate values>!
Obviously, it doesn't go "exactly" like this, but the goal of this post is going to be largely about boring math, so it sounds cooler if we say I'll be talking about black magic, right?
Let's open the grimoires and see how we can answer this sizing question!
Magic wand-width1
The first thing we are going to worry about is the bandwidth, which makes things both super straightforward and sadly also not straightforward in that it involves a bit of guesswork.
The easy-peasy part
Assume Varnish will saturate the network; it's going to be the case in 99.9% of cases. Varnish has a very limited CPU usage, and for large traffic, most of the CPU is going to be consumed by the kernel processing network packets. In reality, this is only going to be a real problem if you are running on a Raspberry Pi, or using a ton of 10G NICs (from experience, a 4×10G setup is not an issue if using IRQ pinning).
Of course, never take the label on the tin at face value "10 Gigabit/s" means you are only going to get around 1GigaByte/s of useful data (80% is a good rule of thumb).
Given the required bandwidth, you are easily able to know how many network cards of what type (1G or 10G) you need, and most of the time, you'll get one NIC per server.
Number of NICs = (required bandwidth) / ((type of NIC) * 0.8)
The "well, that's tricky" part
The issue, of course is to know the required bandwidth. Managers will say "we want to serve X simultaneous users", except it's only half the story. Modern streaming protocols, be they HSS, HLS or DASH, will adapt the video bitrate to the network conditions, meaning mobile users will probably get lower bitrates than, say, fiber users.
The required bandwidth, easily enough, is equal to (concurrent users) * (video bitrate).
The tricky part is settling on that bitrate; here are a few options (spoiler: none of them is excellent):
- pick the highest bitrate available on your platform: play it safe, but drastically raise the required bandwidth (especially with 4k)
- pick the lowest bitrate available: maximize the number of users, but your QoS won't be good.
- split your user base between mobile and desktop: if you know/plan the percentage of mobile users you can lump them together with a lower highest bitrate, and consider the desktop users will get the regular highest bitrate.
- use empirical data: if you already have users, use that! You can easily extract the average bitrate for a user, and use it for the new platform.
As you can see, all of these are variants of "well, guess!", which isn't very satisfying, but that's the best we can do. Traffic is never stable over time, and traffic trends aren't either, so the best plan is to monitor trends, for example using Varnish Custom Statistics and use them to plan for the future.
Processor-cerer2
If your service is using pure HTTP, you can pretty much skip this session as Varnish is super efficient and doesn't consume much CPU (as said earlier, multiple big NICs can be an issue for the kernel though).
If you are using HTTPS, well, it doesn't matter too much either, which may be surprising, but given the context, it makes sense. HTTPS can be a big CPU chewer, but maintaining a SSL/TLS connection isn't that costly, establishing it is. And this is actually our saving grace because video streaming (both live and VoD) tends to reuse connections a lot; typically one stream uses one connection, with a request (for video chunk or manifest) every few seconds. So you really care about peak connection events, and when you deliver live streaming, that can happen a lot: in case of a football/soccer match, or a Game of Thrones episodes, you'll witness a massive influx of users within just a few minutes. But let's think about that.
As a ballpark figure, our own Hitch handles around 3000 new connections per seconds thanks to being a super light TLS terminator (it leaves the HTTP processing to Varnish to focus on encryption). Assuming your video has a 1Mbps bitrate (according to youtube, that's 360p24, pretty low quality), 3000 users will consume 3Gbps of sustained bandwidth, that's a third of the 10Gbps network card you usually find in servers. So, a quad-core processor is sufficient to not be the bottleneck, up the video quality, and it's even less of a problem.
So here, the bandwidth is probably going to be our bottleneck, making the CPU requirements irrelevant. Again: do NOT run a video delivery service on a Raspberry Pi!
Memory-tual3
And here we arrive at the mathiess part of this article, and once again, you'll see things are quite easy because of the live video context.
First question is: how much must we cache? The usual answer: "ALL OF IT!!" doesn't really work here since we are dealing with a stream, so we have to limit ourselves to a certain time range. Obviously, this range is going to be between now and somewhere in the past. In video delivery it's called "DVR" (yes, that DVR, remnant of an not-so-old era) and is just an expressed duration: "I provide 12 hours of DVR".
Even if you don't have DVR capabilities on your platform, you'll still have some video chunk backlog accessible to your user, as the manifest (that lists "current" chunks) will contain a handful of "current" chunks to allow buffering (the list is actually a FIO, with newer chunks pushing older ones out).
So, considering a video stream:

And the portion of it that we need to cache:
 The cache capacity required is the surface of purple rectangle. That was the simple case, and you are probably going to deliver a full matrix of streams because of the combinatorics between:
The cache capacity required is the surface of purple rectangle. That was the simple case, and you are probably going to deliver a full matrix of streams because of the combinatorics between:
- channels
- video quality
- audio quality
- language
- subtitles (arguably, these are going to be negligible)
- ...and various other factors
But the logic is very much the same, your cache capacity is just the purple rectangle:

Cache capacity = (sum of the bitrates of all streams) * DVR
If you have multiple DVRs, you'll need to break that into as many expressions as needed.
Note that contrary to the section about bandwidth, here I treat all qualities/bitrate equally because, given enough users, chances are that all are going to be used. Even if users won't spread evenly across them, we still need to cache them.
One to rule cache them all
From here, there are multiple options, and we quickly touch the simple case of the whole cache fitting in one node.
You have two solutions here: if the cache is small enough and you don't care about cache persistence, for example because you have a short DVR so retrieving content after a restart is not important, you can use the malloc storage to store everything in RAM.
If you need persistence and/or you need to store more than what the memory can hold, then the answer is the Massive Storage Engine. The MSE stores objects on disk, meaning you get way more storage than just using RAM, plus you get the possibility of persisting that cache so it's available again after a reboot. Just plug a few SSDs in your servers and you are good to go!
In any case...
We shard!4
If a node isn’t sufficient, one approach is to shard, i.e. specialize each node (or group of nodes) to maximize your cache capacity because this way each object isn’t replicated on every machine of the layer. The caching capacity of your platform is dictated by this formula:
Total cache capacity = individual cache capacity * number of specialized clusters
Note that this is independent of the size of the clusters. Adding a new machine in an existing group won’t expand your cache size. On the other hand it will provide you with more bandwidth for that cluster. As you’ll see, this will be important.
Channeling your channels
The first instinct is to split your caches by channels, either using DNS or a level-7 load-balancer (hint: Varnish does that very well too), and it’s not a bad idea; you just have to be aware of the pitfalls.
Let’s take a very simple example: you have three Varnish servers, all capable of delivering 10Gbps, and you assigned one channel to each Varnish. The bandwidth may look like this:

Channel2 is a bit more popular, so it gets a bit more traffic, nothing dramatic. But now imagine that channel 3 airs the season premiere of Game of Thrones, and your bandwidth needs may look like this:
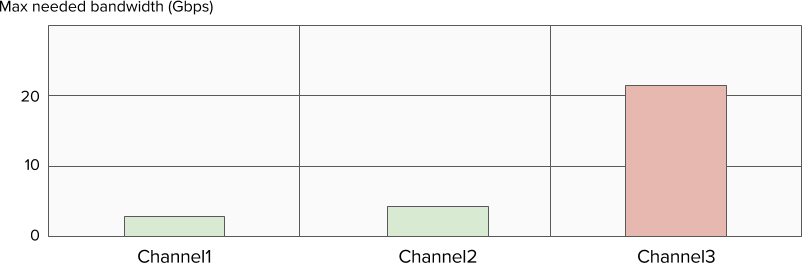
While the total traffic is less than the total potential of your platform, it won't work because by splitting by channel you fragmented your layer, and you now need to monitor each cluster individually and add/remove nodes as the traffic fluctuates.
The upside is that you get a segregation of content that is very easy to conceive and express. At the load-balancing level, it's just a matter of setting up rules using hostname/URL and assigning the proper caching pool.
Note: We've covered the load-balancing subject previously in two blog posts, here and here.
Consistent hashing
One other way is to use consistent hashing as load-balancing strategy (if using Varnish as your LB, it is achieved using the hash or shard director). You wouldn't be specializing your caches per channel but directly per object, i.e. each object systematically gets to the same cluster, but objects inside the same streams aren't necessarily kept together.
The sheer number of objects and quick changes in "current" chunks will ensure that the load is spread more evenly than when segregating per channel and will avoid (to some extent) the caveats of channel segregation.
One aspect that can appear annoying is that the backend selection is now "opaque": the load-balancer will compute a hash from the request and pull out a corresponding backend, apart from the consistency, this is pretty much a black box: for new requests, you have no idea where it will go. That can be a bit frustrating but it doesn't really matter, and that's the important part!
Since all chunks from all channels are all over your caching layer, the "issue" (It's not a real one, as you can tell by the quotes) is to extract meaningful statistics. Once again, Varnish Custom Statistics comes to the rescue: it can aggregate information for a whole cluster, so as long as you can tell the channel/bitrate/type of chunk through URL or headers, it gots you covered. It deserves a whole blog post on its own, so let's leave the implementation details aside for now, but it's super quick to do.
Something something unicorn5
As you can see, live streaming simplifies computation a lot, and ultimately, the only fuzzy part is going to be the output bandwidth. As soon as you get a ballpark estimate, everything else is straightforward, notably thanks to the fact we don't really have to care about CPU.
Storage is still an area where there are interrogations, but they are quickly resolved as soon as you look at the amount of data cached. Once the threshold for MSE is reached, you can go wild. While the RAM limits you to under (roughly) 512G of storage, MSE can reach dozens of terabytes and offers cache persistence, essential for the DVR feature.
The on-demand side of things is another world altogether, so make sure you have a look at our webinar about it!

[1]: Yeah, sorry, that was a bad pun, even by my standards, bear with me.
[2]: I know, I know...
[3]: WHEN WILL THIS STOP!?!!?
[4]: See what I did there?
[5]: To quote a great man: "I know. I'm not even trying anymore." - Archer
Photo (c) 2015 Rafacoutu used under Creative Commons license.


