
This episode of Two Minute Tech Tuesdays is about request coalescing, a core feature in Varnish that is used to reduce the stress on origin servers when multiple requests are trying to fetch the same uncached content.
What happens when multiple clients request the same uncached content from Varnish? Does Varnish open up the same amount of requests to the origin, and potentially destabilize the entire platform under heavy load (the Thundering Herd effect)?
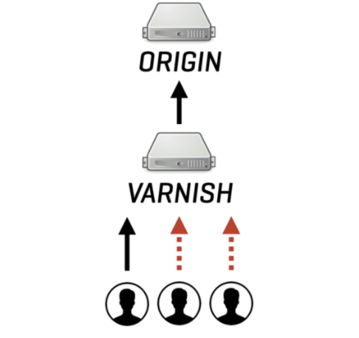
Luckily Varnish is not sensitive to the Thundering Herd. It identifies requests to the same uncached resource, queues them on a waiting list, and only sends a single request to the origin. As the origin responds, Varnish will satisfy the entire waiting list in parallel, so there's no head-of-line blocking: everyone gets the content at exactly the same time. So request coalescing will effectively merge multiple potential requests to the origin into a single request.
The advantages are pretty straightforward:
- Less pressure on the origin server
- Less latency for queued clients
- Overall better performance and scalability
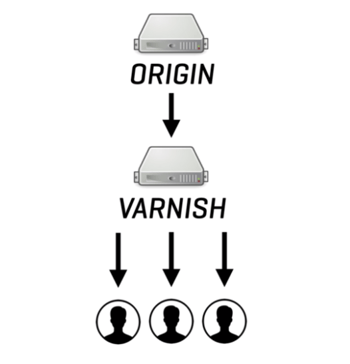
In terms of domains of application, request coalescing is useful for:
- Long tail content that doesn't always end up in the cache
- Caches with limited storage that need to evict objects to free up space
- Short-lived content
- Live video streaming over HTTP where segments are constantly added to the live stream
This only applies to cacheable content. Uncacheable content cannot take advantage of request coalescing. With uncacheable content we mean content that uses set cookie headers, or that has cache control response headers that deliberately bypass the cache. In that case, one needs to bypass the waiting list, and by doing so we avoid potential serialization. With serialization we mean items on the waiting list being processed serially, rather than in parallel. This has a very detrimental effect on the performance and the quality of experience for the user, because in this case there actually is head-of-line blocking.
Luckily Varnish Configuration Language (VCL) has provisions for that:
set beresp.ttl = 120s;
set beresp.uncacheable = true;
And by setting uncacheable to true and assigning a TTL, you're basically making sure these uncacheable objects end up in the hit-for-miss cache. This is useful because it allows you to make the decision ahead of time to bypass the waiting list and to avoid serialization.



