
The recent years we’ve seen a surge in the use of HTTP-based transports for online video. HTTP Live Streaming (HLS), HTTP Dynamic Streaming (HDS) and Silverlight video (Smooth streaming) are seeing quite a bit of usage. These streaming standards are more or less made for caching. However, due to the stateless nature of the HTTP protocol there is a gap between the streams themselves and the underlying traffic. This makes it hard to get proper insight into what is actually going on in the video distribution system.
Varnish Cache, which seems to be a recommended tool by Adobe does video distribution quite well. Still, it is rather hard to get statistics on how much data is served, what streams are being delivered and what variants of the streams are being consumed. This is problematic for both the editorial and business side, who both need to know how the video is being consumed.
Varnish Custom Statistics (VCS) can be a valuable tool to get some insights into what is going on. Here is an outline of how you can set up VCS to gather these data and get real-time information about what content is being consumed.
Identifying individual clients with VCS
The key to getting some useful statistics from VCS when dealing with video is to find a way to uniquely identify each client. The current development version of VCS has the ability to count unique clients accessing a certain object or a certain stream. In order to get VCS to deliver counts of unique clients you need to supply it with a client ID. The easiest way to do this would be to use some sort of a session ID. One could also use the client's IP address but that might be inaccurate. Extract the identity of the client and store it in req.http.identity in vcl_recv for now.Identifying each stream
The next thing we would need to do would be to identify each stream. Each file contains a short bit of video, typically 3-15 seconds longs. On my local Adobe Media Server (AMS) installation, the name of the stream is encoded into the URL of the file. With a regular expression extracting the name of the stream is rather trivial. In the URL below I’ve highlighted the name of the stream.
/hds-vod/sample1_1500kbps.f4vSeg1-Frag29
Extract the name of the stream and store it in req.http.stream for now.
Putting it together
The next thing to do would be to have Varnish deliver the data to VCS. In vcl_deliver we log the transfer to VCS. Use req.http.stream as key and supply req.http.identitystd.log(“vcs-key:” + req.http.stream);
std.log(“vcs-unique-id:” + req.http.identity);
Going deeper. Getting more information about the various streams
One thing is knowing the number of users that are watching a certain stream. There may actually be a few more things of interest to you:
How many people are consuming the various bitrates?
At least AMS also encodes the quality of the stream into the URL of each individual URL. It is quite simple to create one VCS timeseries for each specific bitrate. Use use a regex to grab the bitrate from the URL and put it in req.http.bitrate. Then in vcl_deliver you add another logline like this:
std.log(“vcs-key:” + req.http.stream + “-br-” req.http.bitrate);
std.log(“ vcs-unique-id:” + req.http.identity);
Note that the unique key is only declared once for each transaction. So you don’t need to redeclare it for any other time-series you want to create based on the same HTTP transaction.
Where is each stream being watched?
A lot of the power within Varnish lies in its modules. One really useful module is the GeoIP module, allowing you get geographical information about a client's IP address. If you use the a GeoIP module to store the country code in req.http.country-code pulling this into a separate time-series for each geography is trivial.What devices are people using?
The same technique used for matching up streams with GeoIP data could be used to match it up with information from a Device Description Repository (DDR). You probably want to reduce the number of logical devices into something a bit more manageable the user-agent string itself. Use one of the many DDR VMODs available and create one time-series for each type of device you want. If you want a really simple classification (phone,tablet,pc) you can probably use the VCL-based varnish-devicedetect library. Other alternatives are DeviceAtlas, dClass or Scientia mobiles WURFL Vmod.Great. What would the result of all this be?
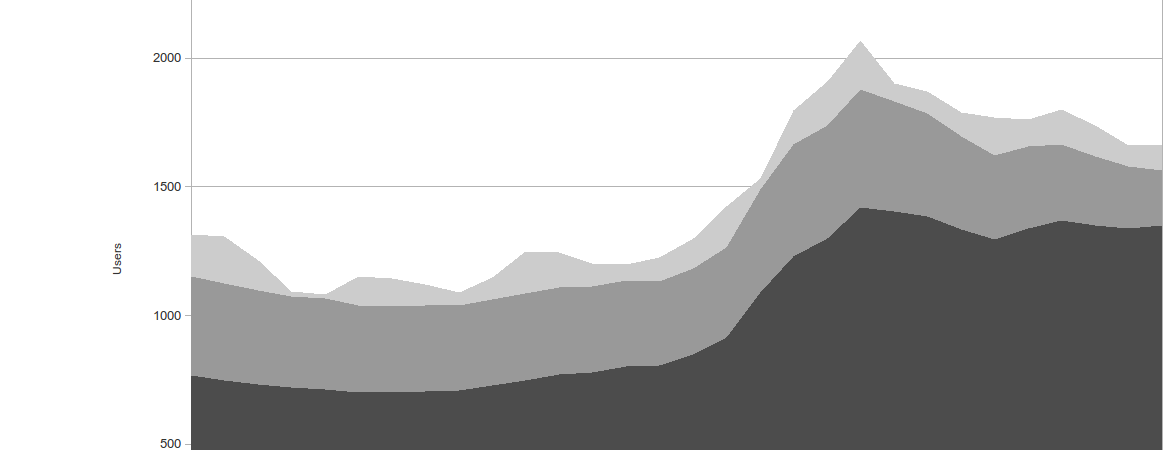
VCS generates timeseries from the keys you provide - in real-time. Each timeseries can be fetched from VCS in JSON or JSONP format, making it rather easy to plug into a visualization tool or a reporting tool, generating something like the image above. The resolution of the timeseries is configurable but you’ll probably want something like 30-90 seconds for each bucket in the timeseries. Also the time-series should be something like 60-180 minutes long. VCS stores the time series in memory so if you have millions of stream you might need a bit of memory.
If you want to persist the information we’ve had good results pumping the data from VCS into PostgreSQL, which seem to handle JSON in a good way. All you hipsters might want to use a spiffy NoSQL database for this. :-)
If you want to give this a spin on your own infrastructure, please let us know. VCS is a pretty useful tool to gain insight into what your Varnish cache instances are doing and we'd love to see it used!