
We just released the latest and greatest version of Varnish High Availability (or VHA as we like to refer to it), our cache replicator, with two main features: multi-cluster support for distributed replication and dynamic backends integration for easier and more versatile configuration.
As our last release was quite a while ago, let me give you a tour of VHA to remind you what it's all about. If you already know what VHA is and does, you can jump directly to the aptly named "What is new in VHA" section where I explain the new features.
What is VHA?
Varnish High Availability is a cache replicator, meaning that it will watch your Varnish traffic (much like varnishlog and varnishncsa do), and push new content to fellow Varnish nodes if they don't have it yet. You may be wondering why we took time to develop such a solution when pure VCL solutions already exist. The reason is very straightforward: it just wasn't good enough.
VCL-based replication works. But it only works well in some very precisely scoped, basic, scenarios and each new feature requires an exponential amount of work, marring the VCL with exceptions and special cases. For example, most VCL-based replication setups work pretty well for two nodes but become crazy to manage once you want to add a third node or support ESI.
So, we set off to create something that would require virtually no configuration nor maintenance, allowing us to keep our sanity and hard-earned sleep hours. We started small and simple, and release after release, here we are, with a much larger feature set:
- Out-of-process, asynchronous replication: VHA works outside of Varnish, meaning that your traffic isn't impacted by it, and that you can disable or enable it instantaneously.
- Easy configuration: installation and configuration take less than 5 minutes and is easily automated thanks to dynamic backends.
- Lightweight: because it is based on HTTP and uses libcurl internally, resource consumption is very low.
- Multi-cluster support: you can replicate to any number of nodes and they can be grouped by cluster to avoid costly cross-cluster bandwidth.
- ESI support: replication respects ESI fragments out-of-the-box, duplicating them accurately and individually.
- HTTPS: Since Varnish Cache Plus supports HTTPS, it made sense that VHA supported it too, securing very easy cross-datacenter replication.
- Low bandwidth usage: VHA will, to the extent possible, keep the bandwidth low by avoiding unnecessary data transfers, and since we profit from Varnish gzip support as well as conditional request for content revalidation, replication won't be a burden for the network.
- Log playback: VHA normally operates on live instances, but for tests, debug and cache warming purposes, it's possible to replay a saved log, or to just use the current backlog.
- Forbid replication from VCL: defaults rules allow VHA to replicate only the noteworthy content, but it's also possible to filter out content directly from your VCL.
What is new in VHA?
Multi-cluster
As mentioned in the introduction, one of the big features in this release is the multi-cluster support. Before 2.0, VHA would replicate to all known nodes to keep things simple. This translated, for clusters, into something like this:
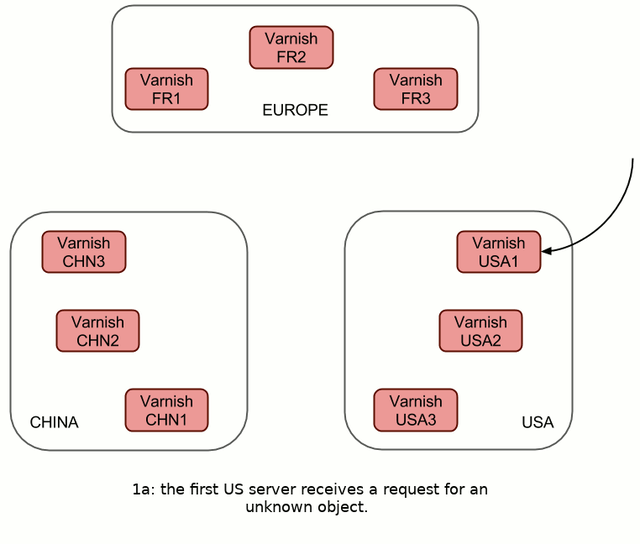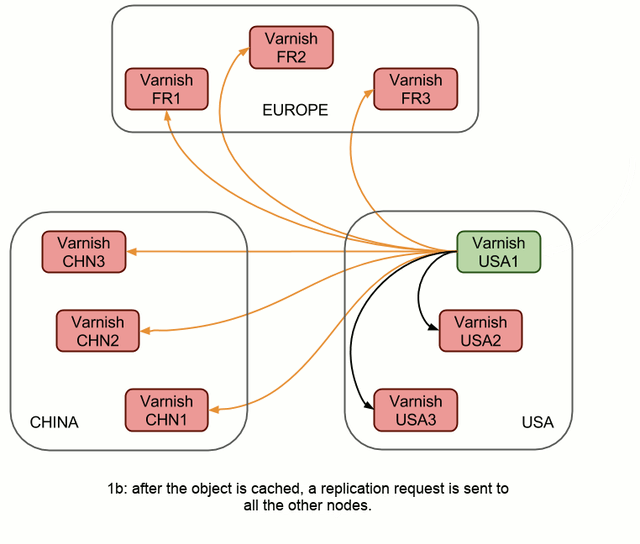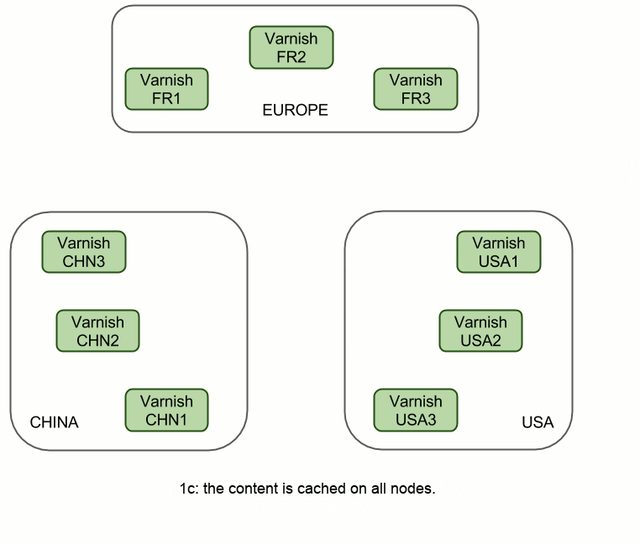 This works great, however, the links across clusters/continents (coloured orange in 1b) can be very costly, and each request is sent six times on those links. Not very efficient.
This works great, however, the links across clusters/continents (coloured orange in 1b) can be very costly, and each request is sent six times on those links. Not very efficient.
So we got smarter, and now VHA 2.0 will react like this:
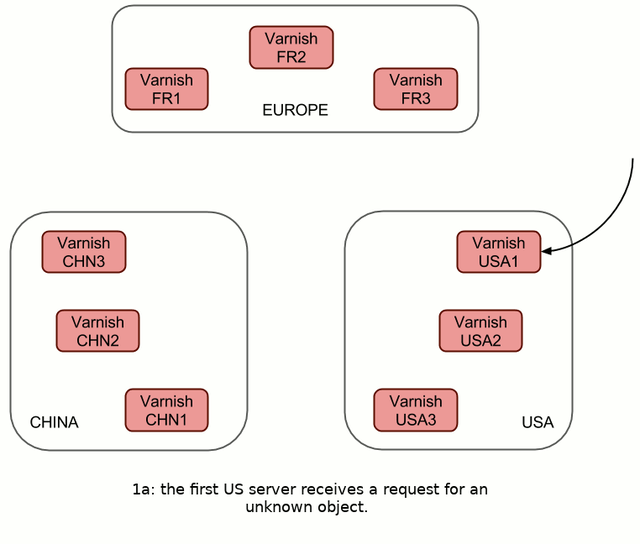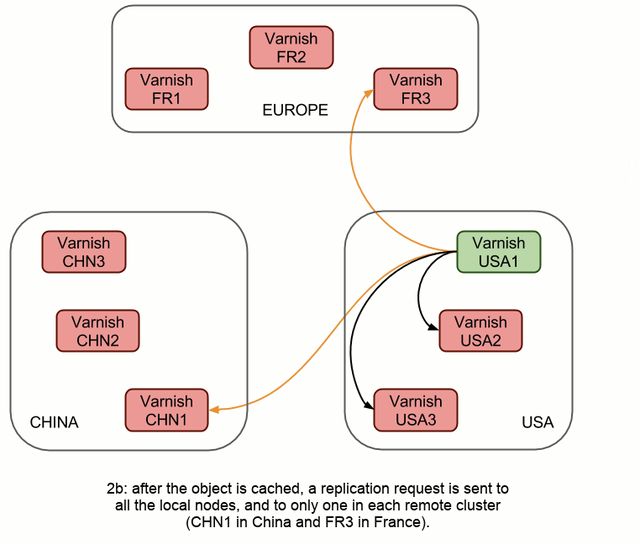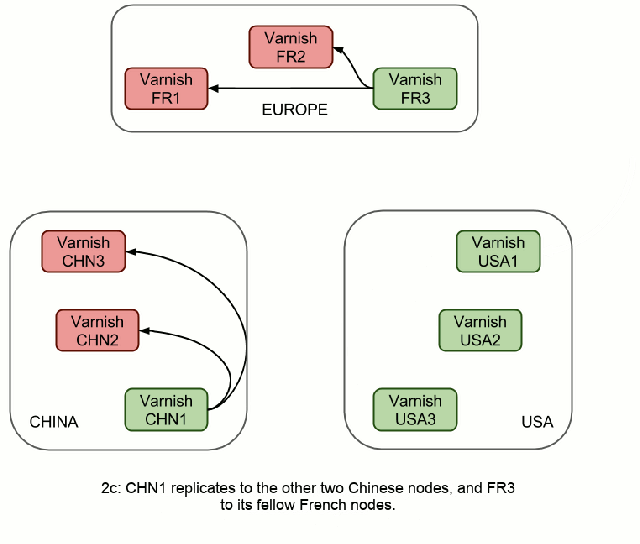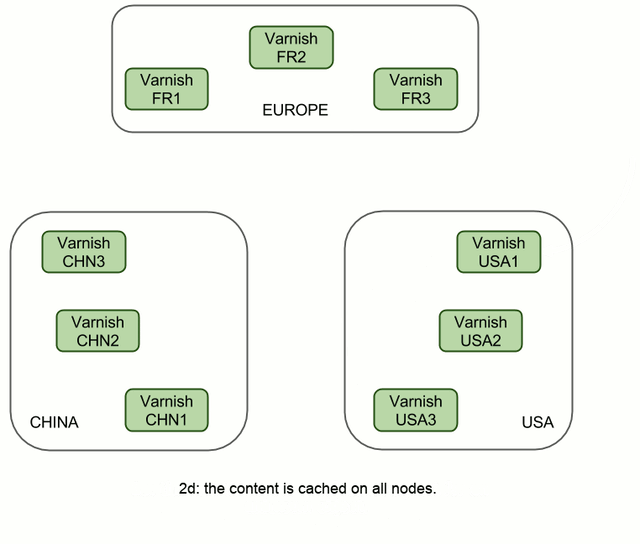 In this case, replication takes one more step (fig 2c), but it's going to be a LAN transfer and a hit on Varnish, so it's going to be virtually instantaneous. However, it does allow us to send only two distant requests instead of six, no matter how many machines there are in these clusters.
In this case, replication takes one more step (fig 2c), but it's going to be a LAN transfer and a hit on Varnish, so it's going to be virtually instantaneous. However, it does allow us to send only two distant requests instead of six, no matter how many machines there are in these clusters.
Dynamic Backends and easy configuration
VHA requires light VCL integration to deliver its full potential and in previous versions, we made things easy by generating the VCL glue from the VHA configuration files (nodes.conf). The annoying part was that when a node went up or down, you had to:
- update nodes.conf
- generate a new vha.vcl based on nodes.conf
- reload Varnish
- reload VHA
Now, we don't have to care about the red lines anymore, decorrelating VHA and Varnish further for better maintainability. Updating nodes.conf is easily automated using DNS, AWS services, or Consul for example, partly because the configuration format is super simple. The three clusters in our previous examples are described by this nodes.conf:
[FRANCE]
FR1 = https://1.1.1.1
FR2 = https://1.1.1.2
FR3 = https://1.1.1.3
[USA]
USA1 = 2.2.2.1:8080
USA2 = 2.2.2.2:8080
USA3 = 2.2.2.3:8080
[CHINA]
CHN1 = http://[1:1:1::1]
CHN2 = http://[3:3:3::2]
CHN3 = http://[3:3:3::3]The notable point here is that this configuration is the same for all the nodes, in all the clusters, and the best part is that VHA is resilient to desynchronization: nodes can be updated one by one or all at once without problem.
The reason this is possible, stems from our dynamic backends vmod: goto. Upon receiving a replication request, VHA will lookup its callback address, resolve it, and use it as backend, EASY! And to keep replication secure, we offer multiple checks to choose from: ACL, IP, Port, token, and in addition, these criterias can be combined together for more fine-grained control.
And more!
Of course, we have been refining the code, and we continued our VSL (Varnish Shared Log) integration to keep expanding our possibilities, notably:
- using a backup VSL file to be replayed for debugging purposes or to warmup fellow caches
- using the live VSL backlog for the same reasons.
- prevent replication from the VCL: for example, if you know a request is not worth caching (say, because its TTL is too short), all you need to do is call "
std.log(vha-instruction: forbid)".
Ask for a trial!
All this makes VHA 2.0 the most solid and easiest version to date, increasing your control over cache replication without losing any of the sweet performance boost we already provided. Request a free trial today if you'd like to try out VHA as part of Varnish Cache Plus.
