
There is a reason why people install Varnish Cache in their servers. It’s all about the performance. Delivering content from Varnish is often a thousand times faster than delivering it from your web server. As your website grows, and it usually grows significantly if your cache hit rates are high, you’ll rely more and more on Varnish to deliver the brunt of the requests that are continuously flowing into your infrastructure.
But, what if there’s a failure?
Hardware is known to fail from time to time, the operating system kernel can have a bad day, or, once in a blue moon Varnish itself may hit a bug and be brought down.
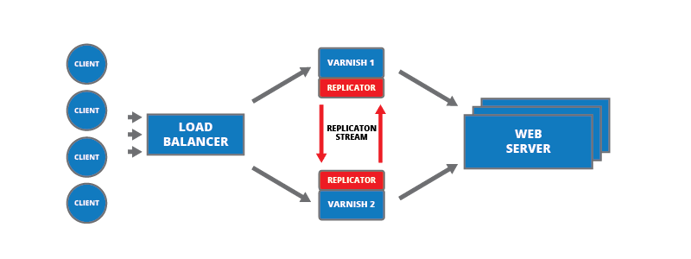
What you see here is a typical Varnish setup. On top you’ll see your client, requesting content, your load balancer, a couple of Varnish server and your web server. There might be other components in play here as well, but these are the essential ones.
What happens if one of your Varnish servers fails?
There are two scenarios, depending on how your load balancer is set up.
It is mostly likely set up two distribute requests in a round robin or random fashion, evenly distributing the requests between the servers. If this is the case you’ll probably handle losing one of the Varnish server in a decent manner, but the costs are twice as many backend requests as needed. If the client requests /foo through Varnish 1 and then another client requests the same URL through Varnish two both of these are likely to hit the backend.
The alternative setup for your load balancer is to have it hash the incoming requests based on the request URL. This will remove the unnecessary requests from hitting your backend but it will generate a massive peak in backend requests as the cache hit rate suddenly drops from the usual 99%+ to around 50%. This might overwhelm the backend.
Our solution: The best of both worlds
We’ve created Varnish High Availability. It is a multi master replication service that allows you to replicate content between Varnish servers. As Varnish gets a new object from the backend it will replicate the object over to it’s peer cache. Since now both servers have the object they can both serve it to clients, removing the need to bother the backend unnecessary.
As you can see this gives you two obvious benefits:
- A significant performance increase.
- Increased resilience.
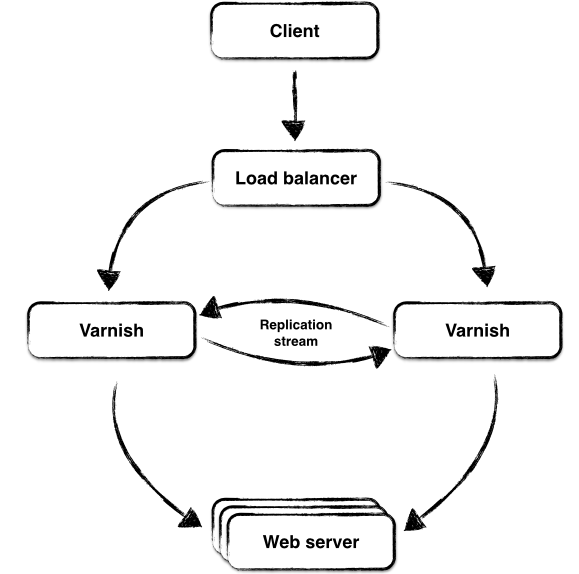
No need for more cluster management software
Since the replication happens automatically and we rely on the load balancer not to send traffic to Varnish servers that are down there is no need to add complex cluster management software to your stack. It is my experience that most of these packages tend to reduce uptime, rather than increase it. Complexity kills update more efficiently than anything else.
Availability
Varnish High Availability is available as part of a Varnish Plus subscription. If you’d like to get these components up and running now, please contact one of our Varnish Plus Sales Executives. Or, if you have any technical questions for us, please feel free to reach out to our technical team.
We’re very excited about this great new software and believe it will go a long way in realizing the true potential of Varnish Plus for your business.

Image is C 2006 Stephen Donaghy, used with Creative Commons 2.0 license.