
Today's episode is about Varnish Discovery, but before we can talk about Discovery, we need to look back at last week's episode about Varnish Broadcaster.
Broadcaster is a system that is used to broadcast messages to multiple systems at once, through a single endpoint. It does so based on the nodes.conf inventory file that contains the full server inventory. The problem with that, as we saw in last week's video, what happens when your inventory changes on a regular basis? You would constantly need to manually update that nodes.conf file, or write software that does it for you. Luckily there is already a system to do it: Varnish Discovery.
Varnish Discovery is an auto-discovery system that is used by Varnish Broadcaster, as well as Varnish High Availability. Its job is to keep the nodes.conf inventory file up to date and notify the Broadcaster of any changes, within a dynamic inventory context. Varnish Discovery supports multiple types of backends, such as DNS, Amazon Web Services, Microsoft Azure and Kubernetes. Varnish Discovery is used to facilitate distributed cache invalidation, cache warm up and cache synchronization.
To understand how Discovery is responsible for adding auto-discovery support to the Broadcaster, look at the following diagram:
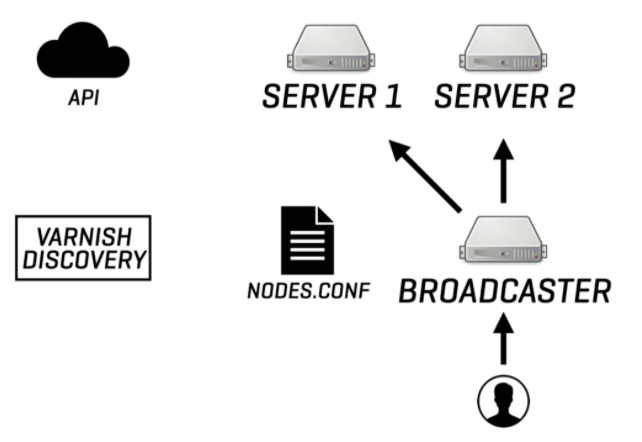
This Broadcaster setup broadcasts messages to two servers, based on information that is stored in the nodes.conf configuration file. Meanwhile, Discovery polls the infrastructure API at regular intervals. When the environment scales out and a third server is added to the cluster, the infrastructure API will be aware of this information. The next polling attempt by Discovery will reveal this information, allowing Discovery to store the new inventory in nodes.conf and signal the Broadcaster that changes have occurred:
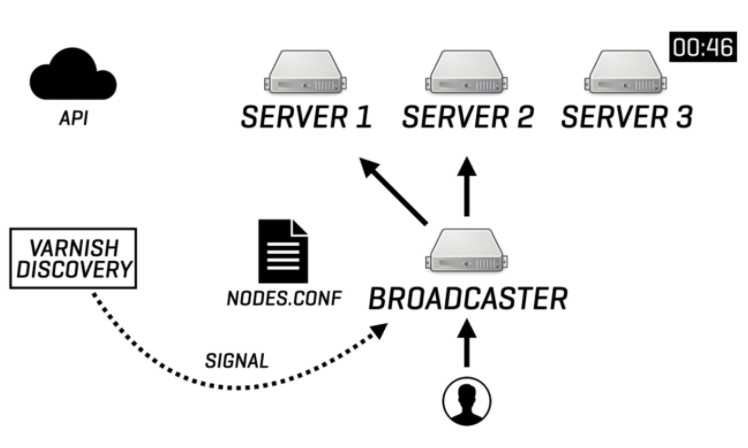
This will allow the Broadcaster to read the contents of nodes.conf and store the new inventory in its internal memory. When the next broadcasting request happens, it will now broadcast messages to all three servers.
Technically, Varnish Discovery is a service that runs alongside your Varnish Broadcaster setup:

Its first argument is the type of backend that is used and the other configuration parameters refer to:
- The location of the nodes on file
- The location of the process ID file
- The group, which refers to the entity that needs to be pulled
The group depends on the backend being used. For AWS, it's the Auto Scaling group. For Azure it’s the virtual machine scale set name, for DNS it's the domain name that needs to be resolved, and for Kubernetes, it's the service endpoint.
Varnish Discovery supports a lot more configuration, but the key thing to remember is that if you have a dynamic inventory, and you want to use the Broadcaster or Varnish High Availability, Varnish Discovery has you covered.
